
The Python Hyperspectral Analysis Tool (PyHAT) provides access to data processing, analysis, and machine learning capabilities for spectroscopic applications. It includes a GUI so you can get straight to analyzing data without writing any code. Or, if you are comfortable writing code, PyHAT can be imported just like any other Python package.

Data Format

Hyperspectral Cubes

Preprocessing
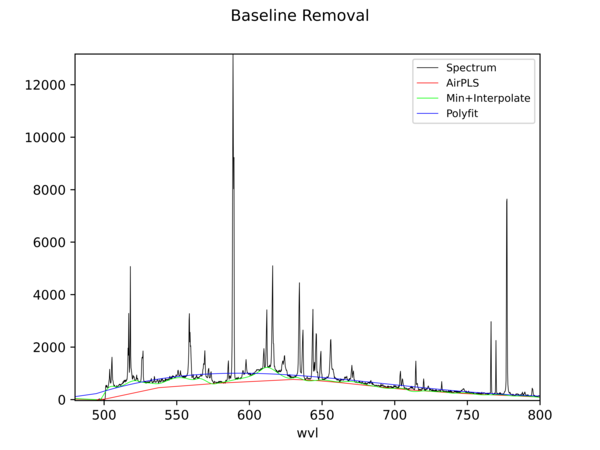
Baseline Removal
Dimensionality Reduction
PyHAT includes a variety of dimensionality reduction methods from scikit-learn and other libraries, including:
- Principal Component Analysis (PCA)
- Independent component analysis (ICA)
- t-distributed Stochastic Neighbor Embedding (tSNE)
- Locally Linear Embedding (LLE)
- Non-Negative Matrix Factorization (NNMF)
- Linear Discriminant Analysis (LDA)
- Minimum Noise Fraction (MNF)
- Local Fisher's Discriminant Analysis (LFDA)

Clustering
Both K-Means and Spectral clustering methods are available in PyHAT. Clusters are stored as metadata columns, and can be used in plotting functions to color-code points.

Outlier Identification

Regression
A significant focus of PyHAT development has been regression: estimation of a quantitative property based on statistical models that have been trained on spectra of known targets. This is the approach used by the ChemCam and SuperCam teams to derive chemical compositions of Mars rocks using LIBS, but it is broadly applicable to many types of data. PyHAT provides easy access to the following regression algorithms:
- Ordinary Least Squares (OLS)
- Partial Least Squares (PLS)
- Least Absolute Shrinkage and Selection Operator (LASSO)
- Ridge Regression
- Elastic Net
- Bayesian Ridge Regression (BRR)
- Automatic Relevance Determination (ARD)
- Least Angle Regression (LARS)
- Orthogonal Matching Pursuit (OMP)
- Support Vector Regression (SVR)
- Gradient Boosting Regression (GBR)
- Local Regression (algorithm developed by the PyHAT team)
Cross Validation

Prediction

The Python Hyperspectral Analysis Tool (PyHAT) provides access to data processing, analysis, and machine learning capabilities for spectroscopic applications. It includes a GUI so you can get straight to analyzing data without writing any code. Or, if you are comfortable writing code, PyHAT can be imported just like any other Python package.
Data Format
Hyperspectral Cubes
Preprocessing
Baseline Removal
Dimensionality Reduction
PyHAT includes a variety of dimensionality reduction methods from scikit-learn and other libraries, including:
- Principal Component Analysis (PCA)
- Independent component analysis (ICA)
- t-distributed Stochastic Neighbor Embedding (tSNE)
- Locally Linear Embedding (LLE)
- Non-Negative Matrix Factorization (NNMF)
- Linear Discriminant Analysis (LDA)
- Minimum Noise Fraction (MNF)
- Local Fisher's Discriminant Analysis (LFDA)
Clustering
Both K-Means and Spectral clustering methods are available in PyHAT. Clusters are stored as metadata columns, and can be used in plotting functions to color-code points.
Outlier Identification
Regression
A significant focus of PyHAT development has been regression: estimation of a quantitative property based on statistical models that have been trained on spectra of known targets. This is the approach used by the ChemCam and SuperCam teams to derive chemical compositions of Mars rocks using LIBS, but it is broadly applicable to many types of data. PyHAT provides easy access to the following regression algorithms:
- Ordinary Least Squares (OLS)
- Partial Least Squares (PLS)
- Least Absolute Shrinkage and Selection Operator (LASSO)
- Ridge Regression
- Elastic Net
- Bayesian Ridge Regression (BRR)
- Automatic Relevance Determination (ARD)
- Least Angle Regression (LARS)
- Orthogonal Matching Pursuit (OMP)
- Support Vector Regression (SVR)
- Gradient Boosting Regression (GBR)
- Local Regression (algorithm developed by the PyHAT team)
Cross Validation
Prediction